
Da Castro Street al resto del mondo

Castro Street è una strada vivace. Si riempie di vita specialmente nei weekend tra caffetterie, ristoranti etnici e librerie.
Nel 2001, Castro Street è stata la prima strada del mondo ad essere catturata. Tramite una fotocamera montata su un pick-up che la percorse lentamente, da nord verso sud, creandone una sua immagine virtuale.
È da questo primo esperimento che sei anni dopo, nel 2007, nasce Google Street View, la più grande e ambiziosa operazione di mappatura stradale della storia.
Partita coprendo Denver, Las Vegas, Miami, New York, e San Francisco, al suo decimo compleanno Street View è arrivata a coprire oltre 16 milioni di chilometri attraverso 83 differenti paesi e negli ultimi anni quei piccoli veicoli dotati di telecamera a 360° hanno continuato a percorrere, catturare e registrare nuove strade, giardini, abitazioni, marciapiedi, parchi e negozi.
Ma la strada di queste macchinette non è sempre stata priva di ostacoli, come racconta Shoshana Zuboff ne “Il Capitalismo della Sorveglianza”. Nel 2010, la commissione federale tedesca per la protezione dei dati annunciò che le operazioni di Google Street View celavano un furto di dati, raccogliendo segretamente dati personali delle reti wi-fi private.
In Canada, Francia e Olanda esperti di tecnologia scoprirono che i dati “aggiuntivi” raccolti comprendevano nomi, numeri di telefono, informazioni sul credito bancario, password, messaggi, trascrizioni di e-mail e chat, dating online, pornografia, informazioni sull’uso del browser, dettagli medici, geolocalizzazione, file audio, video e fotografici.
Si aprono così inchieste da parte della FCC (Federal Communications Commission), di procuratori generali di 38 differenti Stati americani e della già citata Commissione Tedesca, tra le altre.
Ma se la missione di Google è “organizzare le informazioni a livello mondiale e renderle universalmente accessibili e utili.”, questo non vale quando è lei stessa ad essere oggetto di ricerca: Google ammise la raccolta di dati personali senza autorizzazione ma dichiarò che non ne fece alcun uso commerciale e connotò le violazioni della privacy di street view come un errore commesso da un singolo ingegnere al lavoro su un progetto sperimentale.
Il resto dell’azienda, fino ai vertici aziendali, negò di essere a conoscenza dell’esistenza di raccolte di dati personali mentre l’ingegnere in questione si rifiutò di parlare appellandosi al quinto emendamento.
In due anni la FCC richiese cinque affidavit a Google senza ottenere riscontri e l’indagine si risolse un’irrisoria multa per 25.000 dollari per aver ostacolato le indagini.
Per quanto riguarda le inchieste statali Google raggiunse un accordo per una multa di 7 milioni di dollari nel 2013, accompagnata dalla promessa che Google sarebbe stata più attenta al lavoro dei propri dipendenti. Anche l’indagine tedesca non portò a risultati sostanziali nonostante le prove di come tra il 2008 e il 2010 furono raccolti in tutto il mondo 600 miliardi di byte, 200 dei quali negli Stati Uniti.
(Altre cause si sono susseguite negli anni, arrivando ad un nuovo patteggiamento, nel Luglio 2019, pari a 13 milioni di dollari presso la Corte Federale di San Francisco.)
Il primo passo per risolvere un problema è ammettere la sua esistenza. Dieci anni di docce fredde nelle forme di Google Spy-Fi, Cambridge Analytica e innumerevoli casi di data breach hanno creato consapevolezza e il bisogno di una risposta. Cinque anni di lavori da parte del Comitato del Parlamento Europeo su Libertà Civili, Giustizia e Affari Interni, il Consiglio e la Commissione Europea sono risultati in un pezzo storico di legislazione che vede la luce nel maggio 2018: le General Data Protection Rules.
GDPR e l’effetto Bruxelles
“Until I feared I would lose it, I never loved to read. One does not love breathing.”

“Non ho mai amato leggere, fino al momento in cui ho pensato di non poter più farlo. Non è che uno “ami” respirare.” Penguin Books apriva con questa citazione da ‘Il buio oltre la siepe’, la propria mail di aggiornamento delle privacy policy in seguito all’introduzione della GDPR nel maggio 2018.
In quelle settimane infatti, le nostre caselle vennero sommerse di e-mail inattese, tutte uguali alle altre, con nuove condizioni di trattamento dei dati. Da quel giorno ogni nuova visita a qualsiasi pagina online è accompagnata da pop-up o banner, più o meno intrusivi e fastidiosi, per l’accettazione o il rifiuto dei cookies di tracciamento.
La GDPR introdusse nuovi limiti su come le compagnie possono raccogliere e condividere dati senza l’autorizzazione dell’utente. Offre anche ampia autorità ai governi europei di imporre multe fino al 4% del fatturato globale dell’azienda che le infrange o forzare cambiamenti e correzioni nelle pratiche di raccolta dati.
Questa legge venne accolta come la migliore espressione al mondo di tutela dei dati personali nel mondo digitale e fece da modello per nuove regole di protezione della privacy in Brasile, Giappone, India e altri paesi.
Un caso scuola dell’Effetto Bruxelles: quando le condizioni imposte dall’unione europea sono le più stringenti per un prodotto o un servizio, le compagnie non hanno altra scelta che adottarle per rimanere sul mercato europeo e a quel punto diventa inefficiente differenziare prodotti o servizi per differenti aree geografiche.
Così intere supply-chain o, come in questo caso, servizi digitali si adeguano a criteri di sicurezza, requisiti di trasparenza e regole di comportamento definite a Bruxelles, al punto che quanto deciso in Europa diventa uno standard globale attuato nel resto del mondo.
Due anni dopo, a parte l’inondazione di e-mail e la fioritura dei pop-up, i risultati concreti della tanto ben accolta legge sono marginali. L’unico gigante delle Big Tech a essere multato è stata Google, penalizzata con una multa di 57 milioni di dollari ad inizio 2019, senza nessun’altra multa rilevante nei confronti di Facebook, Twitter, Amazon o altri.
“Vision without execution is just hallucination” è una citazione che rimbalza spesso nelle lezioni o nei workshop di strategia aziendale e la sua origine si può tracciare fino ad un antico proverbio giapponese che recita “Un’idea senza azione è solo un sogno. Un’azione senza idea è un incubo.” La GDPR fino a oggi è la storia di una bella idea senza azione.
La legge è stata vittima di mancate applicazioni, scarsi finanziamenti, risorse limitate e tecniche di stallo da parte delle Big Tech. Due casi emblematici sono Irlanda e Lussembrugo. Nessun’altro paese ha infatti lo stesso carico di lavoro quanto l’isola britannica dove risiedono i quartieri generali europei di Google, Facebook, Twitter e LinkedIn tra gli altri.
L’Irlanda ha infatti portato avanti più inchieste, 127 finora, di qualsiasi altro paese, risultando però in nemmeno una singola penalità sotto la GDPR. Il budget irlandese, pari a quasi 17 milioni di euro, è infatti il sesto per grandezza in Europa, mentre quello del Lussemburgo, paese di residenza di Amazon, è pari a 5,7 milioni di euro, pari a circa le vendite del titano dell’e-commerce in 10 minuti.
È evidente come il problema sia lontano dall’essere risolto e la lotta tra Big Tech e difensori della Privacy una questione aperta. È lecito l’utilizzo che Google e le altre fanno dei nostri dati? Vale la pena essere tracciati per ricevere messaggi promozionali personalizzati? Quando vengono raccolti i nostri dati? Quali informazioni vengono registrate? Che utilizzo ne viene fatto? Chi ci protegge nel caso vengano usate in modo inopportuno? Chi viene punito?
E per semplificare un po’ le cose: come cambia il senso di queste domande a fronte dell’emergenza Covid-19?
Le App di Contact Tracing
“I don’t know about you, people, but I don’t wanna live in a world where someone else makes the world a better place, better than we do.”
“Non so voi, ma non voglio vivere in un mondo dove qualcun altro rende il mondo migliore, meglio di noi.” Come tanti dei personaggi di Silicon Valley, Gavin Belson incarna la forma mentis del mondo Big Tech di oggi e dei suoi protagonisti: tanto innovativi ed ambiziosi, quanto egocentrici e competitivi. La corsa allo sviluppo di nuove App di contact tracing ha assunto simili caratteristiche.
Ogni nazione, ogni regione, ogni sviluppatore ha prodotto una propria soluzione, tanto che è difficile contare quante app di questo tipo siano attualmente disponibili o in via di sviluppo, ma potrebbero superare un centinaio.
Alla loro essenza, il fine è raccogliere informazioni – generalmente crittografate – sugli spostamenti dei soggetti che sono risultati positivi al virus, notificare tutti quelli che possono averli incrociati nel periodo di potenziale contagio e, in alcuni casi, verificare che le persone infette stiano rispettando la quarantena.
Utilizzano tecnologie disponibili e ampiamente diffuse su ogni smartphone, quali GPS e bluetooth, per raccogliere e condividere dati, il che le rende facilmente utilizzabili e scalabili ma anche un bersaglio facile per hackers o predisposte a utilizzi di sorveglianza governativa. Senza contare che la velocità (i.e. la fretta) richiesta per il loro sviluppo e lancio, presta il fianco ad ulteriori problemi di sicurezza.
A metà aprile due giganti Big Tech come Apple e Google, che con i loro sistemi operativi coprono larghissima parte degli smartphone su questo pianeta, hanno unito le forze per creare una nuova funzionalità (un API) a supporto del contact tracing – poi rinominata “exposure notification” per stemperare certe preoccupazioni.
Questa soluzione – che utilizza esclusivamente tecnologia bluetooth e non GPS – è quanto di più vicino a uno standard condiviso ed il suo modello decentralizzato (i dati raccolti “restano” sul proprio smartphone) generalmente apprezzato anche dai difensori della privacy.
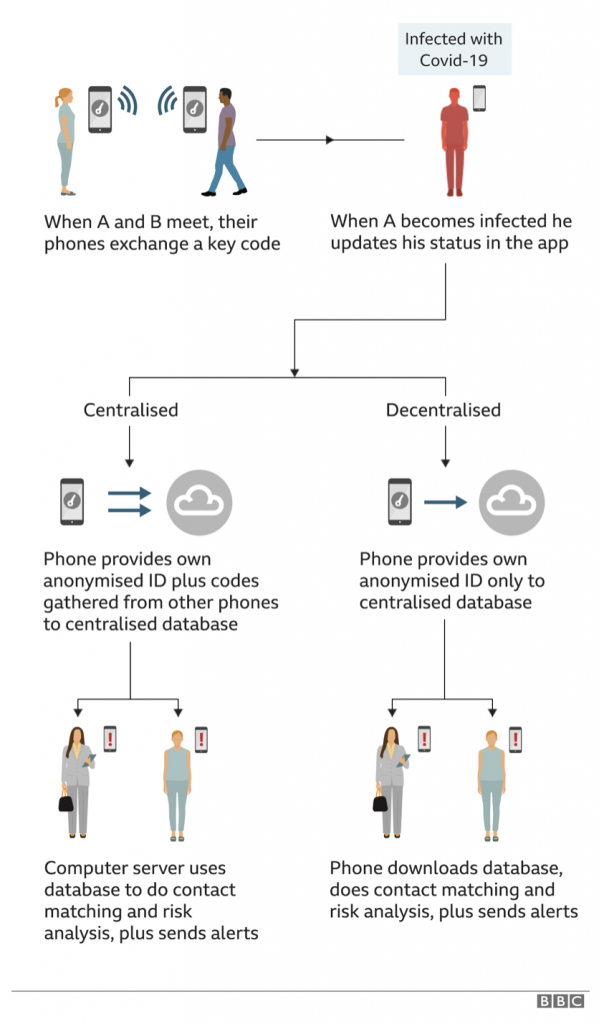
Un modello alternativo è invece quello centralizzato laddove i dati vengono raccolti all’interno di un unico server che contiene i codici dei soggetti tracciati, calcola i rischi di contagio e gestisce le notifiche. Il suo vantaggio principale è una maggiore efficacia nell’analisi dell’andamento dei contagi e un maggior controllo da parte delle autorità sanitarie, al quale si accompagna però necessariamente anche un maggior rischio di re-identificazione dei contatti e di violazioni di sicurezza.
A oggi Italia, Belgio, Svizzera e Germania stanno perseguendo il primo modello (decentralizzato), Francia e Regno Unito il secondo (centralizzato).
Sembra solo corretto a questo punto, con il mondo intero alla ricerca di un modo efficace di tenere traccia del virus, che qualcuno tenga traccia del modo in cui queste soluzioni prendono forma: nasce così il Covid Tracing Tracker Project del MIT.
Un team dedicato di ricercatori sta infatti raccogliendo un catalogo globale delle app approvate ufficialmente dai governi locali cercando di far luce sulle differenti scelte tecnologiche e le loro implicazioni, in termini di protezione dei diritti di riservatezza degli utenti.
Su questo secondo aspetto, il team del MIT considera cinque aspetti determinanti:
- se l’adozione dell’app è su base volontaria o meno;
- se i dati vengono utilizzati esclusivamente per motivi sanitari o anche per altre finalità;
- se l’utente può cancellare i propri dati tracciati, se questi vengono cancellati dopo un certo periodo di tempo o restano memorizzati nei server;
- se i dati raccolti sono “minimizzati” ovvero non viene raccolto alcun dato aggiuntivo rispetto alle finalità di contact tracing;
- infine il livello di trasparenza in termini di condizioni di utilizzo, progettazione e codice utilizzato.
Per qualsiasi riferimento, la raccolta del MIT è disponibile qui. E l’app Immuni possiede un buono score generale tutto sommato.
Si tratta quindi solo degli ultimi dettagli tecnici per raffinare una soluzione efficace? Non esattamente.
Condizioni abilitanti mentre il Titanic affonda
Il successo di qualsiasi soluzione di exposure notification, a supporto del contact tracing, non dipende esclusivamente da scelte tecnologiche ma si basa su alcune condizioni abilitanti fondamentali:
- La capacità di testing – il contact tracing è in realtà una ruota dell’ingranaggio di una strategia più ampia, le 3T Test-Trace-Treat prescritte dal WHO per la gestione delle pandemie.
Studi dell’università di Harvard stimano il volume ideale per gli Stati Uniti a 2,5 milioni di test al giorno per un programma davvero efficace (a fronte dei 145.000 di capacità attuale), secondo le stesse proporzioni il numero di test ideale per l’Italia sarebbe di 457.000 contro la capacità raggiunta a fine aprile di 65.000 tamponi al giorno (che, rapportato alla popolazione, rappresenta comunque uno dei volumi più alti tra i paesi del G20).
Anche la migliore delle soluzioni di contact tracing rischia quindi di essere inefficace senza un’adeguata capacità di testing a supportarla, indipendentemente dalla fase di gestione della pandemia – è notizia di questi giorni come a Wuhan, a fronte di 6 nuovi casi dalla riapertura della prima città entrata in quarantena al mondo, le autorità stiano programmando test per 11 milioni di persone nell’arco di dieci giorni, per contenere il nascere di un nuovo focolaio. - Il tasso di adozione – in economia si parla di esternalità di rete quando il valore di un servizio o un prodotto aumenta al crescere del numero dei suoi utenti. Questo è vero per ogni social network ma anche per altri prodotti classici, come Windows o il telefono di casa.
Un’app di contact tracing basa la propria utilità su il concetto di economia di rete e, in un mondo ideale, raggiunge il suo massimo potenziale quando il 100% della popolazione la utilizza. Dato che però non tutti possiedono uno smartphone, questo tipo di soluzione esclude proprio due dei segmenti più a rischio: chi vive in condizoni di povertà e gli anziani. Diversi studi hanno provato a determinare il tasso di adozione necessario e sufficiente per rendere un’app di questo tipo davvero efficace e i modelli elaborati dall’Università di Oxford pongono la soglia sufficiente al 60% della popolazione totale ma a oggi nessun paese al mondo sembra averla raggiunta.
Secondo dati di fine aprile, a Singapore, paese più volte preso ad esempio nella gestione dell’epidemia, solo il 20% degli abitanti aveva installato l’app a un mese dal lancio, mentre in Norvegia l’adozione è stata più veloce con il raggiungimento del 30% della popolazione in circa due settimane. - Sicurezza e affidabilità – “fail fast to succeed sooner” è un mantra del design thinking e sottolinea l’importanza di procedere per prototipi per arrivare a una soluzione in modo più veloce ed efficiente.
Quando la posta in gioco è così alta però, bisogna valutare bene il peso di quel “fail fast” e gestire l’equilibrio tra una corsa contro il tempo per riaprire in modo rapido e lo sviluppo di un’app per milioni di utenti che gestisca informazioni sensibili in modo sicuro ed affidabile.
Il Regno Unito ha lanciato un pilota controllato nell’Isola di Wight ma ha subito incontrato diverse difficoltà e resistenze (e riscontrato un tasso di adozione comunque insufficiente, pari al 40%). La realtà è che non ci sono spazi per trade-off: una soluzione che non possieda i più alti standard di qualità, che non registri solo i dati necessari, che non sia al 100% sicura da attacchi esterni, che non sia soggetta a falsi positivi o negativi rischia di essere di scarsa utilità, se non deleteria, a fronte di una perdita di controllo sui propri dati digitali.
Alla luce di punti aperti di questa rilevanza, è estremamente difficile semplificare la scelta di adozione e la valutazione costi-benefici in una conclusione netta. Va da sé che le posizioni espresse sia da esperti di settore che opinionisti estemporanei attraversano tutto il ventaglio, dal pieno supporto alla convinta opposizione: “Google conosce tutto di me, spostamenti, negozi e acquisti in cambio di pubblicità e suggerimenti personalizzati. Far ripartire un paese mi sembra un payoff accettabile…”; “Io non sono convinto che funzionerà. Ho solo fatto in modo che faccia il minimo danno possibile, sia che funzioni sia che no.”; “Scaricherò l’app: dei miei dati non me ne frega nulla”; “Perché non installerò nessuna app di contact tracing, episodio 1234567.”
Non tutti gli adepti di Google sono da considerare superficiali, così come non tutti i paladini della privacy sono liquidabili come paranoici. Anche ammesso che si arrivi all’app perfetta, purtroppo il contesto attuale rende difficile convincersi che il 60% di adozione e la capacità di testing necessaria siano obiettivi ragionevolmente alla portata di un sistema come quello italiano e una discussione così accesa sembra quasi voler discutere su quale tipo di remi sia migliore nell’acqua gelida mentre il Titanic sta affondando. Peccato che non ci siano le zattere.
Si tratta quindi di tanto rumore per nulla? Non esattamente.
Tanto rumore per qualcosa: cosa può nascere di buono
Se la vision della GDPR non fosse solo un’allucinazione ma diventasse realtà, se la legge venisse applicata rigorosamente, se la partita tra authority di controllo e Big Tech fosse ad armi pari, se il controllo dei propri dati fosse sempre nelle mani dell’utente… il nostro mondo sarebbe un po’ più pronto ad affrontare una sfida di questa portata.
L’unico modo per non avere preoccupazioni sulla privacy è difenderla, custodirla e rivendicarla e non si tratta di un’idea nuova.
Già due mesi fa raccontavamo di come a fine anni ’90, prima dell’attentato delle Torri Gemelle, l’agenda della Federal Trade Commission includesse un forte giro di vite sulla privacy per le internet companies. Le raccomandazioni a tutela dell’utente includevano set informativi chiari e abbondanti a sua disposizione, possibilità di scelta dell’uso che viene fatto delle sue informazioni, accesso libero alle proprie informazioni personali, diritto alla correzione o cancellazione dei propri dati. In generale, un maggiore controllo e trasparenza.
Venne tutto però messo da parte quando l’interesse alla protezione dei propri dati venne inquadrato come un limite alle pratiche antiterroristiche e la discussione assunse i toni di uno scontro tra privacy e sicurezza, come se non fosse possibile scegliere una senza rinunciare all’altra.
Allo stesso modo, se oggi ci ritroviamo a dover scegliere tra privacy e sopravvivenza, la scelta è naturale. Il problema è che di scelta non si tratta, perché non è assolutamente vero che una cosa escluda l’altra.
Rendere la GDPR qualcosa di più di un’allucinazione richiede una maggiore consapevolezza come società – conseguenza possibile di questo acceso dibattito sulle app – accompagnata da investimenti concreti in termini di budget allocati alle authority di controllo, possibili loro centralizzazioni a livello europeo e accorgimenti sulla customer experience della GDPR stessa.
A titolo di pura suggestione potrebbero essere utili:
- una standardizzazione del formato e dei contenuti dei pop-up di autorizzazione,
- fornire all’utente la possibilità di definire impostazioni di default,
- avere a disposizione una dashboard che raccolga tutti i consensi accettati, i dati condivisi e la possibilità di ritirarli.
Allo stesso tempo è forse arrivato il momento, come consumatori, di riconsiderare l’equilibrio dello scambio tra la propria privacy e la disponibilità di messaggi promozionali personalizzati.
Le Big Tech hanno creato il proprio successo e fondano i propri differenziali competitivi sulla capacità di raccogliere, analizzare e monetizzare i nostri dati. Il caso Street View dimostra come non sia difficile per loro sopravvivere a qualsiasi utilizzo opportunistico e il valore aggiunto di molti dei servizi che utilizziamo quotidianamente sembra quasi farci perdonare qualsiasi loro intrusione nelle nostre vite.
Ritenere che realtà come le Big Tech rinuncino a qualsiasi possibilità di guadagno abbiano a disposizione, estraendo valore dai nostri dati, significa non conoscere la natura stessa di queste organizzazioni – o della raison d’etre di qualsiasi azienda a scopo di lucro.
Una delle critiche più aspre al modello di business di Google, basato sull’advertising, è stata scritta nel 1998: “Ci aspettiamo che i motori di ricerca finanziati dall’advertising siano intrinsecamente sbilanciati a favore di chi paga la pubblicità, a discapito delle esigenze dei consumatori. Questo tipo di pregiudizio è molto difficile da individuare, ma può comunque avere un effetto significativo sul mercato. Riteniamo che il problema dell’advertising abbia tante controindicazioni da rendere fondamentale un motore di ricerca trasparente e accademico”.
Volete conoscere due ardui oppositori delle pratiche di Google? Parlate con i Sergey Brin e Larry Page di 22 anni fa, i suoi stessi fondatori. Pressioni da parte degli investitori, il bisogno di affrancarsi dalla bolla internet del 2000, la ricerca di nuove fonti di guadagno portarono Brin e Page a riconsiderare i principi che loro stessi avevano tracciato nella loro concezione del motore di ricerca: “The anatomy of a large scale hypertextual web search engine”
La competizione con altri giganti – Amazon in primis -, la necessità di sostenere valutazioni miliardarie e le aspettative dei mercati finanziari sono forze altrettanto, se non più, forti per spingere Google a capitalizzare al meglio le risorse – i dati – a sua disposizione a discapito della trasparenza verso i propri clienti.
Realizzare la vision della GDPR, rafforzare i diritti di proprietà sulle proprie vite digitali – e non – e ricalibrare l’equilibrio dello scambio tra dati e pubblicità è una riflessione necessaria e si spera che il dibattito acceso da app come Immuni porti a una maggiore consapevolezza in ogni consumatore.
Altrimenti, come Scout ne ‘Il Buio oltre la siepe’ che non aveva mai amato leggere, il rischio è che anche noi non ameremo mai la privacy, fin quando non ci accorgeremo di averla persa.

Alessandro è Head of Service Design di Generali Italia e co-founder di Mirai Bay con cui collabora come Strategic Advisor per le aree di organizzazione, innovazione e strategia di business.

